Compositional Data?
pyrolite comes with a few datasets from Aitchison (1984) built in which we can use as examples:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyrolite.plot import pyroplot
from pyrolite.data.Aitchison import load_kongite
df = load_kongite()
For compositional data, everything is relative (thanks to the closure property), so we tend to use ratios to express differences or changes between things. However, if we make incorrect assumptions about the nature of our data, we can get some incorrect answers. Say you want to know the average ratio between A and B:
A_on_B = df["A"] / df["B"]
A_on_B.mean() # 2.8265837788402983
np.float64(2.8265837788402983)
Equally, you could have chosen to calculate the average ratio between B and A
B_on_A = df["B"] / df["A"]
B_on_A.mean() # 0.4709565704852008
np.float64(0.4709565704852008)
You expect these to be invertable, such that A_on_B = 1 / B_on_A; but not so!
A_on_B.mean() / (1 / B_on_A.mean()) # 1.3311982026717262
np.float64(1.3311982026717262)
Similarly, the relative variances are different:
np.std(A_on_B) / A_on_B.mean() # 0.6295146309597085
np.std(B_on_A) / B_on_A.mean() # 0.5020948201979953
np.float64(0.5020948201979953)
This improves when using logratios in place of simple ratios, prior to exponentiating means
The logratios are invertible:
np.exp(logA_on_B.mean()) # 2.4213410747400514
1 / np.exp(logB_on_A.mean()) # 2.421341074740052
np.float64(2.421341074740052)
The logratios also have the same variance:
(np.std(logA_on_B) / logA_on_B.mean()) ** 2 # 0.36598579018127086
(np.std(logB_on_A) / logB_on_A.mean()) ** 2 # 0.36598579018127086
np.float64(0.36598579018127086)
These peculiarities result from incorrect assumptions regarding the distribution of the data: ratios of compositional components are typically lognormally distributed, rather than normally distributed, and the compositional components themselves commonly have a Poisson distribution . These distributions contrast significantly with the normal distribution at the core of most statistical tests. We can compare distributions with similar means and variances but different forms, and note that the normal distribution has one immediate failure, in that it has non-zero probability density below 0, and we know that you can’t have negative atoms!
from scipy.stats import norm, poisson, lognorm
means = [[10, 10], [10, 20], [20, 100], [1000, 50]]
fig, ax = plt.subplots(len(means), 4, figsize=(11, 8))
ax[0, 0].set_title("A")
ax[0, 1].set_title("B")
ax[0, 2].set_title("Normal Fit to B/A")
ax[0, 3].set_title("Lognormal Fit to B/A")
ax[-1, 0].set_xlabel("A")
ax[-1, 1].set_xlabel("B")
ax[-1, 2].set_xlabel("B/A")
ax[-1, 3].set_xlabel("B/A")
for ix, (m1, m2) in enumerate(means):
p1, p2 = poisson(mu=m1), poisson(mu=m2)
y1, y2 = p1.rvs(2000), p2.rvs(2000)
ratios = y2[y1 > 0] / y1[y1 > 0]
y1min, y1max = y1.min(), y1.max()
y2min, y2max = y2.min(), y2.max()
ax[ix, 0].hist(
y1,
color="0.5",
alpha=0.6,
label="A",
bins=np.linspace(y1min - 0.5, y1max + 0.5, (y1max - y1min) + 1),
)
ax[ix, 1].hist(
y2,
color="0.5",
alpha=0.6,
label="B",
bins=np.linspace(y2min - 0.5, y2max + 0.5, (y2max - y2min) + 1),
)
# normal distribution fit
H, binedges, patches = ax[ix, 2].hist(
ratios, color="Purple", alpha=0.6, label="Ratios", bins=100
)
loc, scale = norm.fit(ratios, loc=0)
pdf = norm.pdf(binedges, loc, scale)
twin2 = ax[ix, 2].twinx()
twin2.set_ylim(0, 1.1 * np.max(pdf))
twin2.plot(binedges, pdf, color="k", ls="--", label="Normal Fit")
# log-normal distribution fit
H, binedges, patches = ax[ix, 3].hist(
ratios, color="Green", alpha=0.6, label="Ratios", bins=100
)
s, loc, scale = lognorm.fit(ratios, loc=0)
pdf = lognorm.pdf(binedges, s, loc, scale)
twin3 = ax[ix, 3].twinx()
twin3.set_ylim(0, 1.1 * np.max(pdf))
twin3.plot(binedges, pdf, color="k", ls="--", label="Lognormal Fit")
for a in [*ax[ix, :], twin2, twin3]:
a.set_yticks([])
plt.tight_layout()
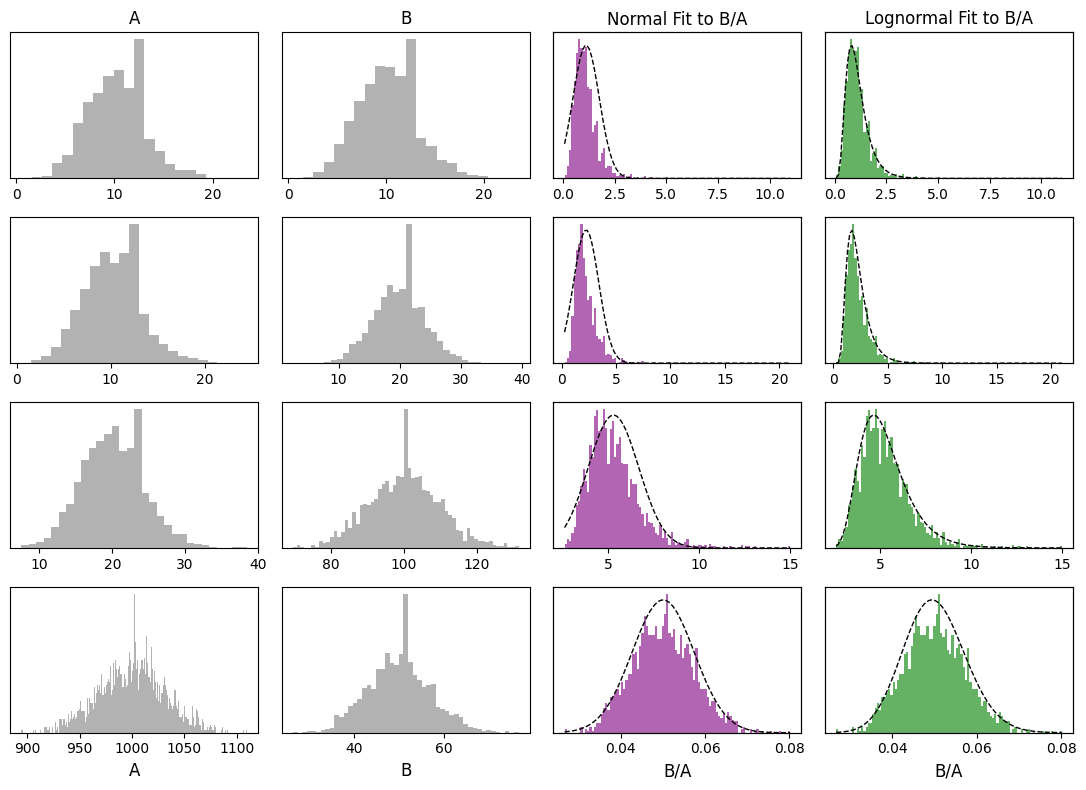
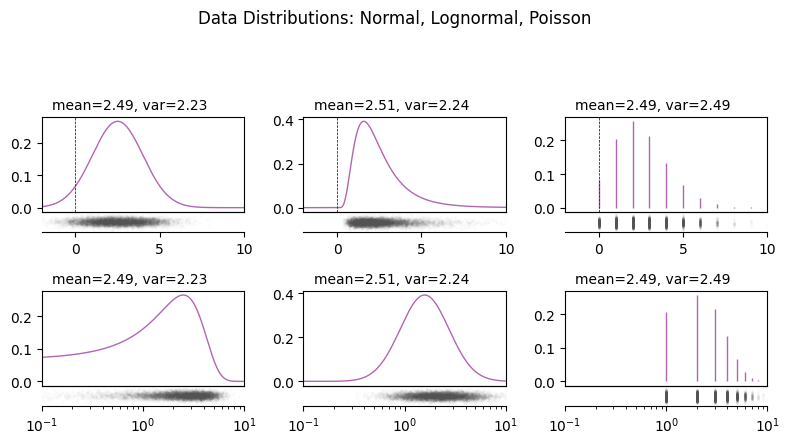
The form of these distributions is a reflection of the fact that geochemical data is at is core a measure of relative quantities of atoms. Quantities of atoms have discrete distributions (i.e. you can have precisely 0, 1 or 6.02 x 10^23 atoms, but 1.23 atoms is not a sensible state of affairs); if you were to count them in a shiny machine, the amount of atoms you might measure over a given period will have a Poisson distribution. If you measure two components, the probability density distribution of the ratio is well approximated by a lognormal distribution (note this doesn’t consider inherent covariance):
from pyrolite.util.plot.axes import share_axes, subaxes
from pyrolite.util.distributions import lognorm_to_norm, norm_to_lognorm
# starting from a normal distribution, then creating similar non-normal distributions
mean, sd = 2.5, 1.5 #
logmu, logs = norm_to_lognorm(mean, sd) # parameters for equival
normrv = norm(loc=mean, scale=sd)
lognormrv = lognorm(s=logs, scale=logmu)
poissonrv = poisson(mu=mean)
We can visualise the similarities and differences between these distributions:
fig, ax = plt.subplots(2, 3, figsize=(8, 4))
ax = ax.flat
for a in ax:
a.subax = subaxes(a, side="bottom")
share_axes(ax[:3], which="x")
share_axes(ax[3:], which="x")
ax[0].set_xlim(-2, 10)
ax[3].set_xscale("log")
ax[3].set_xlim(0.1, 10)
for a in ax:
a.axvline(0, color="k", lw=0.5, ls="--")
# xs at which to evaluate the pdfs
x = np.linspace(-5, 15.0, 1001)
for ix, dist in enumerate([normrv, lognormrv, poissonrv]):
_xs = dist.rvs(size=10000) # random sample
_ys = -0.05 + np.random.randn(10000) / 100 # random offsets for visualisation
for a in [ax[ix], ax[ix + 3]]:
a.annotate(
"mean={:.2f}, var={:.2f}".format(np.mean(_xs), np.var(_xs)),
xy=(0.05, 1.05),
ha="left",
va="bottom",
xycoords=a.transAxes,
)
a.subax.scatter(_xs, _ys, s=2, color="k", alpha=0.01)
if dist != poissonrv: # cont. distribution
a.plot(x, dist.pdf(x), color="Purple", alpha=0.6, label="pdf")
else: # discrete distribution
a.vlines(
x[x >= 0],
0,
dist.pmf(x[x >= 0]),
color="Purple",
alpha=0.6,
label="pmf",
)
fig.suptitle("Data Distributions: Normal, Lognormal, Poisson", y=1.1)
plt.tight_layout()
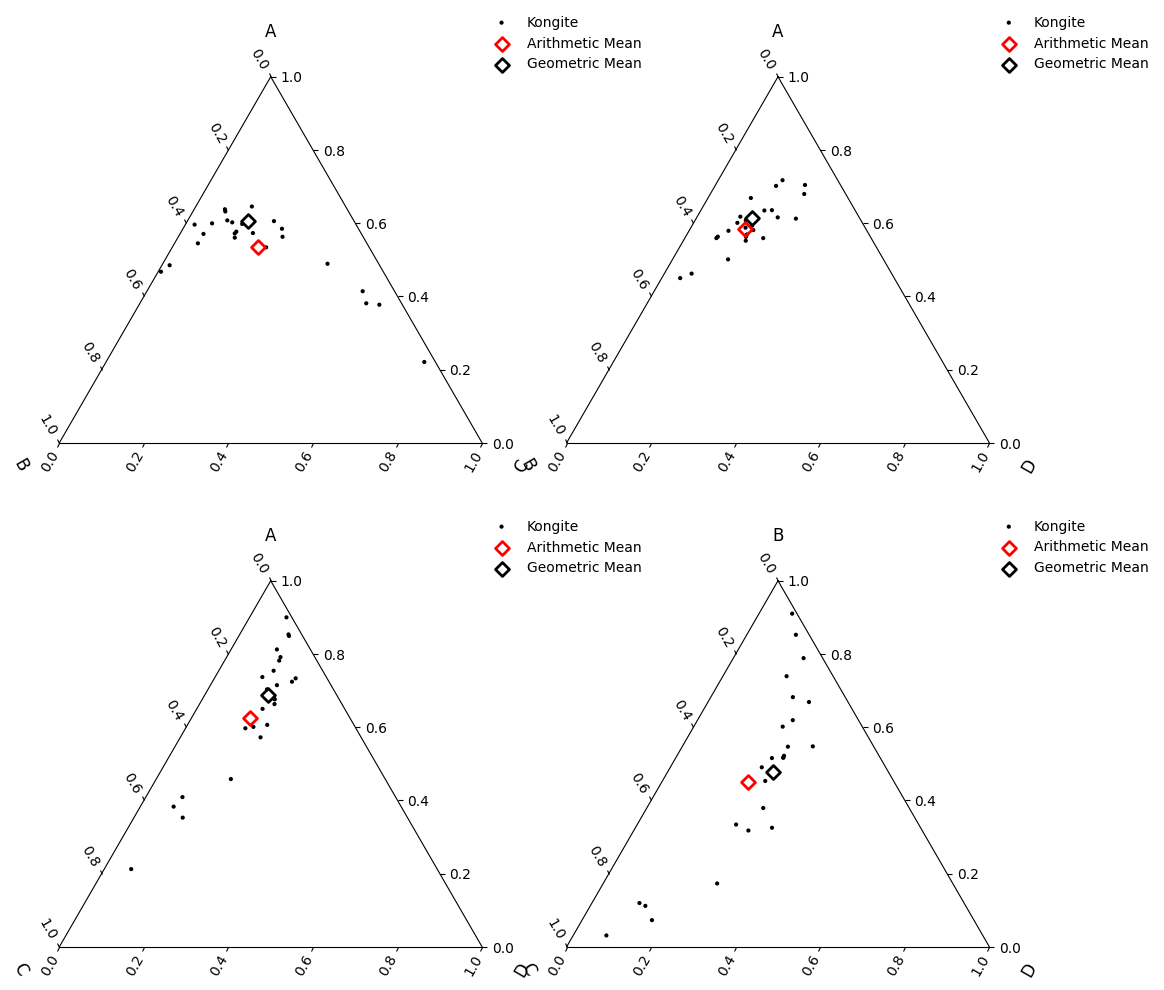
Accounting for these inherent features of geochemical data will allow you to
accurately estimate means and variances, and from this enables the use of
standardised statistical measures - as long as you’re log-transforming your data.
When performing multivariate analysis, use log-ratio transformations (including the
additive logratio alr(), centred logratio
clr() and isometric logratio
ilr()). In this case, the logratio-mean is implemented for
you:
from pyrolite.comp.codata import logratiomean
import itertools
fig, ax = plt.subplots(2, 2, figsize=(12, 12), subplot_kw=dict(projection="ternary"))
ax = ax.flat
for columns, a in zip(itertools.combinations(["A", "B", "C", "D"], 3), ax):
columns = list(columns)
df.loc[:, columns].pyroplot.scatter(
ax=a, color="k", marker=".", label=df.attrs["name"], no_ticks=True
)
df.mean().loc[columns].pyroplot.scatter(
ax=a,
edgecolors="red",
linewidths=2,
c="none",
s=50,
label="Arithmetic Mean",
no_ticks=True,
)
logratiomean(df.loc[:, columns]).pyroplot.scatter(
ax=a,
edgecolors="k",
linewidths=2,
c="none",
s=50,
label="Geometric Mean",
axlabels=True,
no_ticks=True,
)
a.legend(loc=(0.8, 0.5))
See also
- Examples:
- Tutorials:
- Modules and Functions:
Total running time of the script: (0 minutes 4.159 seconds)